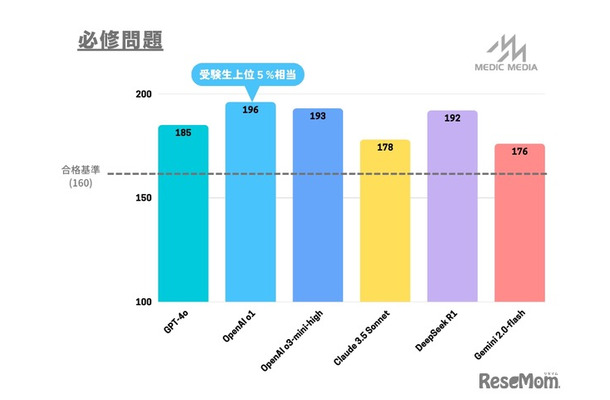
メディックメディアは、2025年2月8、9日に行われた第119回医師国家試験の問題を、複数のAIモデルに解かせてその実力を検証した。検証の結果、使用したAIモデルはいずれも合格ラインを大幅に上回った。一方で、日本特有の制度や法律を問う問題や、優先順位を判断する問題、ごく基本的な計算問題の正答率が低い傾向もみられた。 近年発展が著しい生成AIサービスが医療分野でも診断補助や教育活用への期待を集める中、メディックメディアは2025年2月8、9日の第119回医師国家試験の問題について、複数のAIモデルに解かせて実力を検証。その結果を公表した。 検証の結果、使用したAIモデルはいずれも合格ラインを大幅に上回った。中でもOpenAI o1は必修問題で196点/200点(得点率98%)で受験生の上位5%、OpenAI o3-mini-highは必修問題以外の問題で288点/300点(得点率96%)で受験生中第3位を記録し、トップレベル受験生並みの成績だった。一方で、日本特有の制度や法律を問う問題や、優先順位を判断する問題、ごく基本的な計算問題の正答率が低い傾向もみられた。 医師国家試験は医師免許を取得するための試験で、年に1回行われる。医学に関する幅広い知識が問われ、合格率は例年90%前後となっている。 今回の検証では、GPT-4o(OpenAI)、OpenAI o1(OpenAI)、OpenAI o3-mini-high(OpenAI)、Claude 3.5 Sonnet(Anthropic)、DeepSeek-R1(DeepSeek)、Gemini 2.0-flash(Google)の6つのAIモデルが使用された。いずれのモデルにも参考情報などは提供せずに回答させた。 メディックメディアでは、検証結果を受けて「少なくともペーパーテストにおいては、AIが十分な医学知識を有していることが前提となりつつあると考えられます。一方で、実際の診療現場における判断力や患者対応といった実践的な医療スキルにおいては、依然として人間の医師が中心であり、AIがその役割をすぐに代替するものではありません」とコメント。今回の検証結果を生かし、ユーザーに対してより質の高い、正確かつ効率的な学習・情報提供コンテンツの開発に努めるとしている。
 一流の講師陣がライブ配信「日曜朝最先端探訪」4-7月全6回
一流の講師陣がライブ配信「日曜朝最先端探訪」4-7月全6回